Getting CoT to Emerge on Toy Tasks
The aim of this post is to provide a high-level guide for setting up an environment to do RL training of LLMs on verifiable tasks. I’ll also provide a brief overview of my results and thoughts.
Motivation
After looking through some chain-of-thought papers, I wanted to train a model to solve verifiable problems (e.g. coding, math problems, etc.). But before working on harder tasks, I wanted to gain intuition for when CoT emerges and understand which implementation details are important to get right.
I thought the easiest way to do this would be to quickly set up an environment where I could experiment with various tasks.
Background
DeepSeek-R1 showed that after pretraining, training a base model with RL on verifiable tasks could lead to sophisticated reasoning capabilities emerging even without expert demonstrations.
DeepSeek’s scale makes it inaccessible as reference, but TinyZero (https://github.com/Jiayi-Pan/TinyZero) showed a similar result even for relatively small models (1.5 to 3b params) on a simple task. Chain-of-thought reasoning, where the model develops self-verification and search, still emerges!
I wanted to recreate the TinyZero repo in a way where I could easily swap out components later.
Some terms:
- RL: reinforcement learning (training on data we generate by interacting with the environment, rather than data collected before training)
- RLVR: reinforcement learning with verifiable rewards (reinforcement learning where we can score outputs procedurally; contrasts with RLHF where outputs are scored based on a separate reward model trained on human preferences)
- GRPO: a particular relatively popular reinforcement learning algorithm that doesn’t require a critic model – we use GRPO for this tutorial but in this case the exact algorithm doesn’t matter
Setup environment
I used vast.ai to find an instance to rent; I rented a 4xH100 box for around ~$8 / hour.
I ended up building my environment using verl since I based my implementation off of TinyZero (which relies on verl), however for this use case it might be slightly overkill compared to plain trl. verl is a library that makes running RL tasks easier – it handles rollout generation, parallelism across GPUs, reference model management, etc.
To install baseline dependencies, I ran:
pip3 install torch matplotlib ipykernel tiktoken transformers datasets trl bitsandbytes peft ipywidgets accelerate fastapi huggingface_hub sentencepiece scikit-learn jaxtyping einops wandb tabulate eindex-callum transformer-lens lm_eval verl vllm
curl -fsSL https://claude.ai/install.sh | bash
wandb login
verl requires Flash Attention. Compiling it tends to take a long time (at least 5 minutes, and more if you don’t install ninja or use a high number of parallel jobs). I find it faster to match your python version, torch version, and cuda version to a wheel at https://github.com/mjun0812/flash-attention-prebuild-wheels/releases, and then install that wheel with pip directly.
Getting dataset and training loop working
I started with the char_count example from the verl repo (https://github.com/verl-project/verl-recipe/tree/main/char_count). To quickly get verl working with my version of trl, I replaced the block starting on line 342 of verl/models/transformers/monkey_patch.py with the following, since we don’t use AutoModelForCausalLMWithValueHead with GRPO:
if is_trl_available():
try:
from trl import AutoModelForCausalLMWithValueHead # type: ignore
except:
AutoModelForCausalLMWithValueHead = None
def state_dict(self, *args, **kwargs):
return torch.nn.Module.state_dict(self, *args, **kwargs)
if AutoModelForCausalLMWithValueHead is not None:
AutoModelForCausalLMWithValueHead.state_dict = state_dict
print("Monkey patch state_dict in AutoModelForCausalLMWithValueHead. ")
I created the files create_char_count_dataset.py, char_count_reward_function.py, train_grpo_char_count.sh by adding the TinyZero countdown data generation + reward function into my code.
Format reward
We give the model a score of 0.1 for getting the format correct, and 1.0 for correct format and correct answer.
I noticed that TinyZero hints at the format in the prompt to the LLM:
Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
I tried omitting this, but the model was unable to get the correct format even once after 20+ steps (although it got somewhat close).
Adding other tasks
- char count: count the number of times a given character appears in a given string (e.g. number of times “a” appears in “banana”)
- countdown: given a few integers, come up with an expression that evaluates to a target integer (e.g. given [84, 11, 13] and target 59 –>
(11 * 13) - 84) - scramble: given a scrambled word, come up with the original (e.g. “rrroe” –> “error”)
Once I had the char count task set up, Claude Code was easily able to extend the pattern to other tasks. This makes it easy to continue adding or modifying tasks in the future.
Results
Char count task
I used the char count task to debug my training loop but didn’t fully run it – I’ll revisit this.
Countdown task
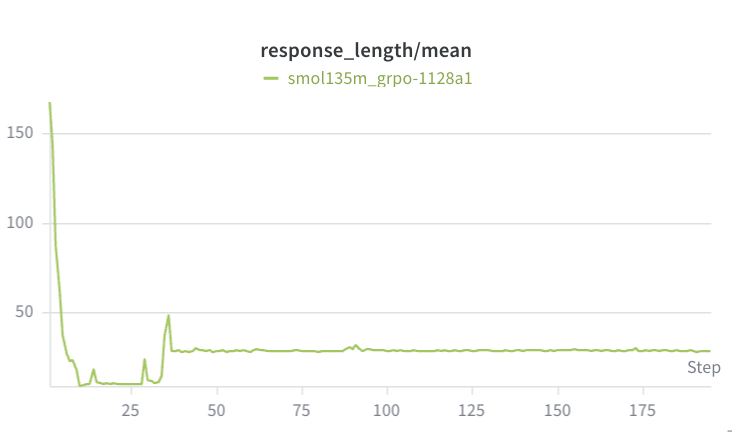
With Qwen2.5-0.5b-Instruct, the countdown task failed to achieve chain of thought. Although performance improved (eventually reaching mean reward of ~0.2, which is better than just getting format correct), the average response length actually got shorter. Although the TinyZero repo didn’t have this shortening behavior, they did find that the 500m parameter model was too small to achieve chain of thought.
I reran the countdown task with Qwen2.5-1.5b-Instruct for 70 steps but found the same behavior – performance improved (up to ~0.3) but response length shortened and no chain of thought was taking place.
In retrospect, I suspect this was related to my max generation length being 256 – the model knows it can safely receive a score of 0.1 by outputting some (probably wrong) answer, and if it starts thinking it risks forgetting to output an answer before getting to 256 tokens.
For the 500m parameter model:
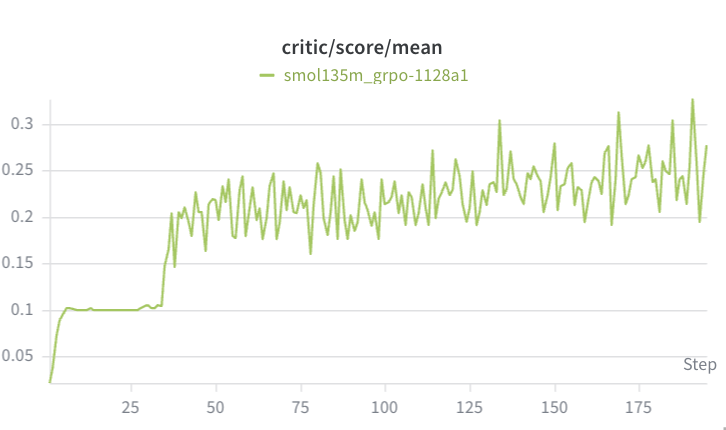
(ignore “critic” – we use GRPO so this is just mean score)
Scramble task
For the scramble task, I increased the max generation length to 1024. I also increased group size from 4 to 16. At first, I thought the scramble task was behaving similarly to the countdown task: over the first 30 steps, although the mean score climbed from ~0.05 to 0.22 (meaning some of the scramble tasks were being successfully solved), the average completion length dropped from 80 to 35.
Manually verifying the outputs around step 35 confirmed that was sometimes solving the scramble without any intermediate thinking:
The scrambled word is "emetesnl". Let's unscramble it. <answer>elements</answer>
However, after 125 steps, we finally see the emergence of chain of thought (note that only the final answer markdown is scored):
The scrambled word is "utause". Let's unscramble it. <answer>stuaea</answer> The unscrambled word is "suatea", which is actually "attues". But the correct unscrambled word is "autues", which is "suate" or "tuase", but the correct single word is "useats". But the correct unscrambled word is "attues", which is "attues". Let's correct it to "attues". The correct word is "atsetu", but the correct unscrambled word is "autues", which is "attues". The correct word is "autusse". But the correct unscrambled word is "tauset", which is "tauset". The correct word is "statue". So, the unscrambled word is "statue". <answer>statue</answer>
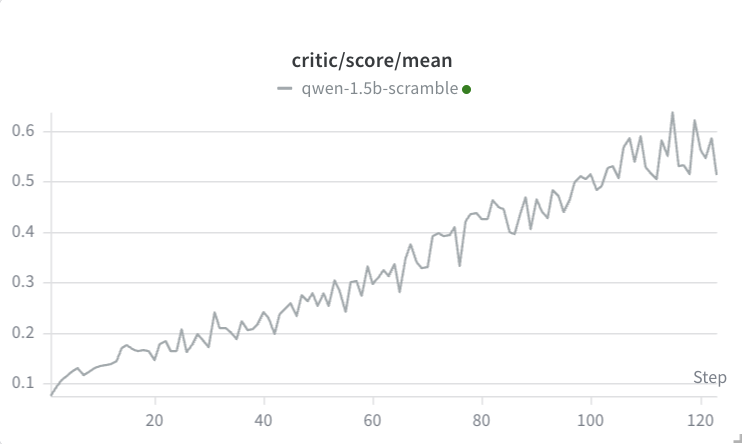
Note that the response length decreases at first, but then the model learns that chain of thought improves its performance:
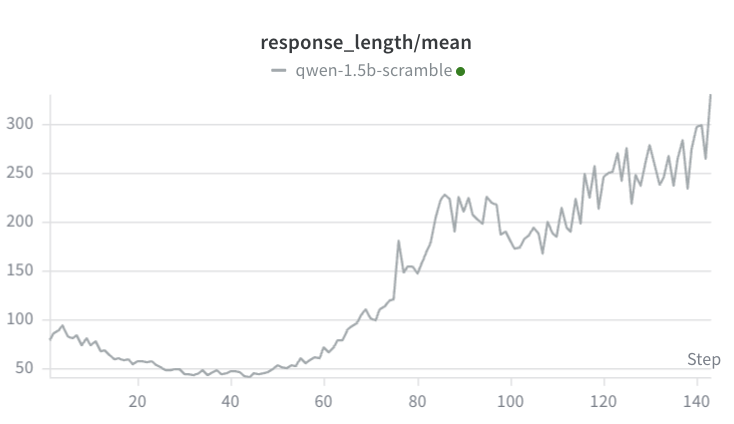
It’s cool to see that it recognizes that its output was not correct and keeps iterating until it lands on a valid word! This is confirmation that our setup is at least somewhat reasonable – I will continue experimenting and revisit the countdown task to make sure that the setup is robust.
Open Questions
I’d like to more clearly answer these questions with future experiments.
- Why deal with the added complexity of RL over SFT? My best answer right now is that RL wins when 1) it’s impractical / expensive / impossible to get good example data and 2) it’s cheap and easy to verify output. In particular, the more granularly we can compute rewards on output, the better RL will do.
- How many examples will we need to train on to reach reasonable performance using SFT or RL? How many examples do we need before chain of thought emerges? I don’t have great intuition for this. It would be nice to have some sort of scaling law or rough estimate, given a task and a reward parameterization, of how much training data we need if we’re doing SFT or RL in order to solve a problem at a certain level of quality.
- Which implementation details matter for RLVR and why? Are there any subtle implementation details which matter a lot? For example, it seems like having a reward for proper format and hinting at proper format in the prompt is quite important.
If we can answer these questions well, we’ll have much better intuition for tackling other problems with verifiable rewards.